
Logmanagement
Log-Dateien – das IT-Tagebuch
Wer möchte dieses Tagebuch mit den äußerst interessanten und aufschlussreichen Informationen nicht gerne lesen? Vor allem Administratoren, Problemanalytiker, Security-Experten und IT-Forensiker sollten hieran sehr großen Gefallen finden und diese Informationen auch für ihre tägliche Arbeit nutzen. Doch immer dann, wenn es bedeutsam zu werden scheint, befinden sich plötzlich fast unüberwindbare Hürden auf diesem Weg. Das IT-Tagebuch ist wahnsinnig dick, wie findet man die interessierenden Informationen? Die Schrift ist in vielen Bereichen unleserlich und teilweise sogar in einer unklaren Sprache verfasst, braucht man dafür einen Dolmetscher?
Datenflut Ereignis
Jedes IT-System und nahezu jedes IT-Gerät schreibt Dateien mit mehr oder weniger relevanten Informationen über das gerade stattfindende Ereignis, eine Datenflut die es zu beherrschen gilt. Diese so geschriebenen Dateien sind in sich zwar schlüssig, untereinander jedoch nicht kompatibel und teilweise auch nicht im Klartext lesbar.
Doch diese in den Log-Dateien enthaltenen Informationen geben Aufschluss sowohl über das gerade stattfindende Ereignis als auch über die gesamte Historie, so dass die Notwendigkeit einer Auswertung für nahezu alle mit der IT-Beschäftigten relevant erscheint.
Effizienz der Analyse
Der Administrator will wissen, ob seine Systeme fehlerfrei laufen und braucht hierfür entsprechende Monitor- und Reporting-Funktionen. Der Problemanalytiker hat eine Störung gemeldet bekommen und soll diese nun z.B. durch Auswertung relevanter Ereignis-Informationen zu diesem Thema beheben. Der Security-Experte muss erkennen können, ob gerade ein Angriff stattfindet und darauf schnellstmöglich reagieren. Der Forensiker analysiert ein in der Vergangenheit stattgefundenen Ereignis und muss auf historische Datensätze zugreifen können.
Alle diese Tätigkeiten benötigen die in den Log-Dateien abgespeicherten Informationen. Aus Gründen der Effizienz muss ein komfortabler Zugriff auf diese Dateien gewährleistet sein. Dieser Zugriff kann jedoch erst dann ermöglicht werden, wenn die Systeme in der Lage sind, diese Log-Dateien zu sammeln, speichern, normalisieren, zentralisieren und zu analysieren. Ein solches Verfahren wird Log-Management genannt. Je nach Unternehmensziel und Aufgabenstellung werden sich unterschiedliche Analyse-Anforderungen ergeben, weshalb auch unterschiedliche Systeme zum Einsatz kommen können.
Log-Auswertesysteme
Die Auswertung von Log-Dateien ist vor allem für die Sicherheit des Unternehmens von immenser Bedeutung. In diese Log-Dateien werden alle relevanten Ereignisdaten geschrieben, ob diese die angeschlossenen Systeme, das Netzwerk oder die Websites betreffen. Diese Ereignisse sind in der Lage normale Events als auch Anomalien aufzuschreiben, so dass hieraus Schlüsse gezogen werden können. Eine Auswertung dieser Log-Files kann je nach Aufwand mit unterschiedlichen Methoden und entsprechenden angepassten Erfolgsaussichten erfolgen:
- Eine Untersuchung der Größe der Log-Dateien liefert einfachste Ergebnisse über eine veränderte der sonst normalen Verhaltensweise von Logeinträgen.
- einfachere Auswertetools können zumindest schon einige interessante Ergebnisse liefern, wie z.B. der Total Network Monitor. Es ist ein Tool zur langfristigen und kontinuierlichen Überwachung der Leistungsfähigkeit des Netzwerks, einzelner Rechner und der Systemtools; alarmiert den Administrator auf verschiedenen Wegen, sobald es Unregelmäßigkeiten oder Fehler feststellt. Ein anderes aus einer Vielzahl von Tool wäre z.B. der Webalizer, der als Logfile-Analyse-Programm für Web-Server vorgesehen ist.
- Ein komplexes Analysetool, wie z.B. Graylog ist in Kombination von weiteren Tools in der Lage aussagekräftige Ergebnisse zu liefern und vorkonfigurierte Alarme zu kommunizieren. Damit ist Graylog in der Lage ein sensorbasiertes Monitoring und Analyse-System zu liefern, in welches alle verschiedenen Arten von Log-Dateien einfließen können.
- Kommerzielle Analysetools wie ElasticCloud bieten eine komplette Lösungsvielfalt an ohne hierfür wesentliche zusätzliche Einstellungen zwischen den einzelnen Komponenten vornehmen zu müssen und ist auch wegen der enormen Skalierbarkeit eher für den Enterpreise-Einsatz zu empfehlen.
- Eine SIEM (Security Information und Event Management) ist ein softwarebasiertes Technologiekonzept mit dem ein ganzheitlicher Blick auf die IT-Sicherheit ermöglicht wird und wird dadurch auch eher für den Enterprise-Einsatz empfohlen.
Aufbau von Log-Dateien
IT-Systeme, wie z.B. Server, Workstations, Router, Switches, Firewalls, Webserver protokollieren Ereignisse und tragen diese Daten in sogenannte Log- bzw. Protokolldateien ein. Diese Dateien dienen als Informationsquelle beispielsweise bei der Problemanalyse oder bei der Rekonstruktion von Transaktionen. Ereignisse werden in der Log-Datei mit Zusatzinformationen nachvollziehbar gespeichert und ermöglichen die nachträgliche Analyse. Wegen der Menge der auftretenden Ereignisse und der damit verbundenen Größe der Dateien kann es vorkommen, dass Daten überschrieben werden. Sollen diese Dateien für einen längeren Zeitraum aufgehoben werden, müssen diese archiviert werden. Durch die Archivierung von Log-Dateien lassen sich Ereignisse über große Zeiträume dokumentieren.
Zur Speicherung der Log-Dateien existieren verschiedene Formate. Viele davon sind mit normalen Texteditoren lesbar und somit allgemein analysierbar. Dieser textbasierte chronologische Aufbau ist typischerweise zeilenorientiert, so dass ein Ereignis mit dessen Zusatzinformationen genau einer Zeile entspricht. Ein Ereignis besteht normalerweise aus den folgenden Informationen:
- Zeitstempel mit Datum und Uhrzeit des Eintretens des Ereignisses
- Signifikanz des Ereignisses (z.B.: Kritisch, Warnung, Fehler, Information, Debug, Trace)
- Quelle des Ereignisses (z.B. IP-Adresse)
- Information über die Art der Meldung
- Zielsystem
Log-Dateien verschiedener Systeme
Microsoft
Bei Microsoft-Systemen werden die Ereignisdateien vor dem Schreiben verschlüsselt und befinden sich hiernach in dem Verzeichnis %SystemRoot%\System32\Winevt\Logs und sind im *.evtx-Format abgespeichert. In der Ereignisanzeige sind diese Dateien in den vier größeren Abschnitten und deren Unterabschnitte einsehbar und unterschieden:
- Benutzerdefinierte Ansichten
- Administrative Ereignisse
- Windows-Protokolle
- Anwendung
- Sicherheit, wie z.B.
- Erfolgreiche Anmeldungen (ID=4624)
- Missglückte Anmeldungen (ID=4625)
- Anschluss eines neuen Speichergerätes (ID=4663)
- Installation eines neuen Dienstes (ID=4798)
- Installation
- System
- Weitergeleitete Ereignisse
- Anwendungs- und Dienstprotokolle
- …
- Ereignisabonnements
Linux
Auf Linux-Systemen befinden sich unter /var/log mehrere Log-Dateien, unter anderem auch die wesentlichste Datei, syslog. Syslog ist ein gängiges Protokoll zur Ereignisprotokollierung für Linux. Anwendungen senden Nachrichten, die auf dem lokalen Computer gespeichert oder an einen Syslog-Sammler übermittelt werden können.
Weitere Log-Dateien sind:
- log loggt alle Meldungen im Bereich Authentifizierung
- log loggt alle Meldungen des Linux-Kernels
- log loggt Meldungen des Mailservers
- syslog loggt alle Meldungen mit Ausnahme von Meldungen der auth oder
authpriv Facilities
Es gibt viele Systeme, die sich um Protokollverarbeitung bemühen, teils mit unterschiedlichem Fokus (Performance, Funktionalität, Einfachheit…).
Webserver
Die Logfiles sind immer nach dem gleichen Schema aufgebaut, wodurch sich das Lesen wesentlich vereinfacht. So gibt es im Wesentlichen 3 Log-Dateien
- Access Log
Der Aufbau sieht wie folgt aus:- IP-Adresse des Besuchers
- Benutzername (wenn Passwortschutz), bzw. „-„
- Zeitpunkt des Zugriffs (inkl. Zeitzone)
- Die Anfrage des Besuchers. Hier ist die verwendete HTTP-Anfragemethode (hier GET), die angefragte Datei (robots.txt) und die genutzte Version des HTTP-Protokolls einsehbar
- Der HTTP-Statuscode, mit dem der Server geantwortet hat (z.B. 404)
- Die Größe der Serverantwort in Bytes
- Der HTTP-Referer, sofern gesetzt. Ist keiner gesetzt, erscheint hier nur ein Bindestrich
- Der User-Agent des Besuchers.
- Die vom Besucher aufgerufene Domain.
- Error Log
Im error.log werden sämtliche Fehlermeldungen notiert, die durch PHP oder CGI-Scripte entstehen oder es handelt sich um Meldungen des Webservers direkt.- Zeitpunkt des Zugriffs
- Webservermodul, in dem der Fehler aufgetreten ist. Hier zum Beispiel das „Autoindex“ Modul
- Die Prozess-ID des Webserverprozesses
- Die IP-Adresse des Besuchers
- Fehlercode und Fehlermeldung
- FTP Log
Die hier eingetragenen Meldungen sind sehr einfach gehalten und beinhalten die folgenden Informationen- FTP Befehl, wie STOR, RETR, DELE, MKD
- FTP-Benutzer
- Größe der Datei in Bytes
- IP-Adresse des Systems, der die Aktion ausgeführt hat
- Zeitpunkt des Zugriffs (inkl. Zeitzone)
- Datei oder Verzeichnis, welches bearbeitet wurde
Nutzen von Log-Dateien
Aufgrund der Vielzahl der Log-Dateien ist es praktisch nicht möglich alle diese Dateien im Auge zu haben und deren hierin enthaltenen Ereignisse zu sichten. Dabei dienen Sie nicht nur zur Fehleranalyse, sondern auch zur Erkennung von ungewöhnlichen Verhaltensweisen. Aus diesem Grund werden Log-Dateien äußert stiefmütterlich behandelt – trotz ihrer vielschichtigen und interessanten Einträge.
Durchaus verständlich ist deshalb die Arbeitsweise, Log-Dateien erst dann zu sichten, wenn Fehler erkannt werden um diese dann zu analysieren und zu beseitigen. Wesentlich wichtiger ist jedoch die Sicherheitsbetrachtung, die es nicht zulässt, erst dann tätig zu werden, wenn ein Sicherheitsproblem in Erscheinung tritt. Hierfür sind Systeme notwendig, die eine kontinuierliche Aufnahme und Visualisierung der Log-Dateien ermöglichen. Sollte dann auch noch die Möglichkeit bestehen, Alarme bei vorgegebenen Ereignissen auslösen zu können (und vielleicht auch gleichzeitig eine Abschaltung des erkannten Systems vorzunehmen) wäre es absolut perfekt.
Doch sind hierfür einige Schwierigkeiten zu meistern:
- Die zu betrachtenden Log-Dateien liegen in unterschiedlichen Formaten vor
- Die Log-Dateien müssen aus unterschiedlichen Systemen gesammelt werden
- CVE und CVSS Listen müssen mit den Einträgen in den Log-Dateien abgeglichen werden
- Es dürfen keine Informationen auf dem Weg von der Übernahme bis zur Analyse verloren gehen
Die Systeme zur Sammlung von Log-Dateien und deren Analyse gibt es in unterschiedlichen Ausprägungen, als reine Open Source Lösungen bis hin zu großartigen kommerziellen Lösungen. Welche Systeme zum Einsatz kommen sollen, hängt in erster Linie von der Größe des Unternehmens, der Aufgabenstellung und natürlich auch vom Anspruch der Ergebnisse ab. Eines haben die Systeme allerdings gemeinsam, man muss sie alle an die jeweilige vorhandene IT-Struktur und Situation anpassen, mehr oder weniger.
Beschreibung der Log-Systeme
SideCar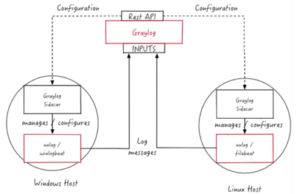
Graylog Sidecar ist ein leichtes Konfigurationsmanagementsystem für verschiedene Protokollsammler, auch Backends genannt. Die Graylog-Knoten fungieren als zentraler Hub, der die Konfigurationen von Protokollkollektoren enthält. Auf unterstützten Geräten / Hosts, die Nachrichten erzeugen, kann Sidecar als Dienst (Windows-Host) oder Daemon (Linux-Host) ausgeführt werden.
Die Protokollkollektorkonfigurationen werden zentral über die Graylog-Weboberfläche verwaltet. In regelmäßigen Abständen ruft der Sidecar-Daemon mithilfe der REST-API alle relevanten Konfigurationen für das Ziel ab . Bei der ersten Ausführung oder wenn eine Konfigurationsänderung festgestellt wurde, generiert (rendert) Sidecar relevante Backend-Konfigurationsdateien. Dann werden diese neu konfigurierten Protokollkollektoren gestartet oder neu gestartet.
Syslog-NG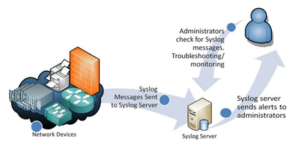
Das Tool wurde entwickelt, um Syslog-Datendateien (ein etabliertes Client-Server-Protokoll für die Systemprotokollierung) in Echtzeit zu verarbeiten. Im Laufe der Zeit wurden jedoch andere Datenformate unterstützt: unstrukturiert, SQL und NoSQL. Wie das Syslog-Protokoll funktioniert, ist in der folgenden Abbildung recht gut zusammengefasst.
syslog-ng ist ein zuverlässiges Tool zum Sammeln und Klassifizieren von Protokollen in Produktionsqualität
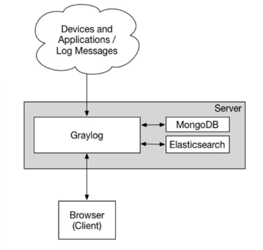
Graylog
Ein Protokollierungs- und Visualisierungs-Werkzeug für die Darstellung und gleichzeitige Alarmierung von speziellen (gefilterten) Ereignissen.
Graylog verwendet für das Speichern der Logs Elasticsearch und kombiniert Logstash und Kibana. Im Gegensatz zu einem ELK-Stack ist Graylog sehr einfach und schnell aufgesetzt. Es bietet ein ansprechendes GUI und User Management. Über LDAP lässt sich sogar ein Active Directory anbinden. Zudem besitzt Graylog eine Vielzahl an integrierter Inputs (Quellen und Formate von Logs) und bietet eine REST-API. Für die initiale Einrichtung ist fast keine Konfiguration notwendig.
Dieses minimale System-Setup besteht aus der Graylog-Weboberfläche, dem Graylog-Server, Elasticsearch-Knoten zum Speichern von Protokolldaten und zur Bereitstellung von Suchfunktionen für Graylog sowie MongoDB zum Speichern von Konfigurationsdaten.
Graylog unterstützt viele Eingabetypen ab Werk. Weitere Eingaben sind auf dem Graylog-Marktplatz verfügbar. Derzeitig unterstützt Graylog Folgende Inputs:
- Syslog (TCP, UDP, AMQP, Kafka)
- GELF (TCP, UDP, AMQP, Kafka, HTTP)
- AWS (AWS-Protokolle, FlowLogs, CloudTrail)
- Beats / Logstash
- CEF (TCP, UDP, AMQP, Kafka)
- JSON-Pfad von der HTTP-API
- Netflow (UDP)
- Einfacher / roher Text (TCP, UDP, AMQP, Kafka)
Der Graylog Marketplace ist das zentrale Verzeichnis der Add-Ons für Graylog. Es enthält Plugins, Inhaltspakete, GELF-Bibliotheken und weitere Inhalte, die von Graylog-Entwicklern und Community-Mitgliedern erstellt wurden.
Logstash
Daten liegen oftmals verstreut oder in Silos auf verschiedenen Systemen in unterschiedlichen Formaten vor. Logstash unterstützt eine Vielzahl von Inputs, die Ereignisse aus verschiedensten verbreiteten Quellen gleichzeitig auslesen können. Logstash dient der Unterstützung von großen Datenmengen und kann im Normalfall unberücksichtigt bleiben.
Elasticsearch
Elasticsearch empfängt Rohdaten aus einer Vielzahl von Quellen, wie Logs, Systemmetriken und Webanwendungen. Dazu werden die Rohdaten im Rahmen des Ingestionsprozesses geparst, normalisiert und angereichert. Anschließend werden sie in Elasticsearch indexiert. Nach dem Indexieren in Elasticsearch können Nutzer komplexe Abfragen starten und mittels Aggregationen komplexe Zusammenfassungen ihrer Daten abrufen. Kibana bietet dann die Möglichkeit, die Daten auf vielfältige Weise zu visualisieren, die entsprechenden Dashboards mit anderen zu teilen und den Elastic Stack zu verwalten.
Kibana
Kibana ist eine kostenlose und offene Frontend-Anwendung, die auf dem Elastic Stack aufsetzt und Such- und Datenvisualisierungsfunktionen für in Elasticsearch indexierte Daten bietet. Kibana wird deswegen auch als das Fenster in den Elastic Stack bezeichnet. Neben seiner Funktion als Visualisierungstool für den Elastic Stack (ehemals als ELK Stack bezeichnet, wobei „ELK“ für „Elasticsearch, Logstash und Kibana“ steht) dient Kibana auch als Benutzeroberfläche für die Überwachung, Verwaltung und Absicherung von Elastic Stack-Clustern sowie als zentraler Hub für integrierte Lösungen, die auf dem Elastic Stack entwickelt wurden. Kibana wurde 2013 in der Elasticsearch-Community entwickelt und hat sich seither zu einem Zugangsportal und Fenster in den Elastic Stack für Einzelnutzer und Unternehmen entwickelt. (Die vorstehende Einführung wurde dankenswerterweise von https://www.elastic.co/de/what-is/kibana zur Verfügung gestellt)
Wegen der programmtechnischen Verbindung von Graylog und ElasticSearch kann Kibana zusätzlich zu den graphischen Ausgaben von Graylog installiert und verwendet werden. Kibana bietet flexible Möglichkeiten, die Daten aufzubereiten und visualisieren zu können.
Beispielhaftes Unternehmens-Netzwerk
Normalerweise besteht ein Unternehmen aus
- Windows-Servern
- Windows-Clients
- Linux-Workstations
- Web-Server
- Netzwerk-Komponenten
- Switches
- Router
- Firewall
Hieraus ergeben sich die unterschiedlichsten Arten von Log-Dateien:
- Windows-Logs
- Linux-Logs
- Syslogs
- Web-Server-Logs
- Hardware-Logs
Damit wird folgender im Normalfall eintretender Netzwerkverkehr erzeugt (hin und zurück):
- Internet -> Firewall -> Switch -> Server -> Arbeitsplatz
- Arbeitsplatz -> Server -> Switch -> Firewall -> Internet
Um nun mit den erzeugten (und interessanten) Logfiles arbeiten zu können, müssen diese an einem zentralen Log-Server gesammelt werden. Am sinnvollsten existiert hierfür eine spezielle Appliance, die an dem Mirrorport des Root-Switches innerhalb des Unternehmens angeschlossen ist, so kann der gesamte Netzwerkverkehr über diesen Port aufgenommen werden. Weiterhin ist das Holen der Logfiles von den übrigen Geräten (Server, Workstation, Firewall) und damit das Zusammenfassen dieser Dateien für ein gelungenes Logmanagement notwendig. Diese nun in komprimierter und einheitlicher Weise vorliegenden Log-Dateien werden an das Log-Management-System Graylog weitergeleitet, wo sie in erster Linie visualisiert werden.
Open Source Software zeichnet sich nicht nur dadurch aus, dass diese frei verfügbar (möglicherweise unter Beachtung der GPL-Lizenz) eingesetzt werden kann, sondern auch, dass die unterschiedlichen Komponenten klar definierte Schnittstellen aufweisen. So kann eine sinnvolle und funktionelle Kombination erfolgen.
- Sidecar
Diese Software wird auf Windows-Systemen installiert, deren Eventdateien verwendet werden sollen. Diese Dateien werden mit diesem Tool an den Log-Server geschickt. Sidecar beinhaltet das Tool Winlogbeat, welches früher alleine für den Transport verantwortlich gewesen ist. - Filebeat
Filebeat wird für die Sammlung lokaler Textdateien verwendet, die in den Microsoft-Event Channel Logs nicht vorhanden ist. Dabei arbeitet Filebeat sehr ökonomisch und behält die Position in der Sammlung der Informationen bei, selbst auch bei Neustarts, so kann die immer wiederkehrende Neusammlung vermieden werden. - Suricata
Suricata wird als ein IDS/IPS-System bezeichnet, ein Intrusion Detection / Prevention System. In erster Linie dient es der Erkennung von Netzwerkanomalien, also Angriffen auf das Netzwerk. Suricata beinhaltet ein Regelwerk von Anomalien, welches einer generellen Pflege unterliegt und auch selbst erweitert werden kann. Derzeitig beinhaltet das Regelwerk über aktive 20.000 Einträge.
Filter für Microsoft Alerts
https://www.elastic.co/de/blog/monitoring-windows-logons-with-winlogbeat
Der Grund für die Überwachung erfolgreicher Anmeldungen besteht darin, nach gefährdeten Benutzeranmeldeinformationen zu suchen. Die Anzahl der erfolgreichen Anmeldungen kann ein wichtiger Indikator dafür sein, dass gefährdete Anmeldeinformationen für das Crawlen des Systems oder andere böswillige Aktivitäten verwendet werden.
Ein Ereignis mit der Ereignis-ID 4624 wird von Windows für jede erfolgreiche Anmeldung unabhängig vom Anmeldetyp (lokal, Netzwerk, Remotedesktop usw.) protokolliert .
Wenn wir in Kibana einfach eine Datentabellenvisualisierung erstellen würden, die alle Ereignisse mit der Ereignis-ID 4624 zeigt, wären wir mit Rauschen überfordert und es wäre nicht einfach, abnormale Benutzeranmeldemuster zu erkennen. Es gibt also mehrere Filterungsschritte, die wir anwenden werden, um das Rauschen zu entfernen. Jeder der Filter wird unten beschrieben.
| Filter | Beschreibung |
|---|---|
| event_id:4624 | Dadurch werden alle Anmeldeereignisse in der gesamten Domäne ausgewählt. |
| !event_data.LogonType:0 | Dadurch wird der Anmeldetyp 0 gefiltert, der für Systemkonten verwendet wird. |
| !event_data.LogonType:5 | Dadurch wird der Anmeldetyp 5 gefiltert, der für Dienstkonten verwendet wird. |
| !event_data.TargetUserName: "ANONYMOUS LOGON" | Dadurch werden anonyme Anmeldungen ( http://windowsitpro.com/systems-management/disabling-logging-anonymous-logon-events ) gefiltert, die normalerweise harmlos sind. Anonyme Benutzer haben äußerst eingeschränkte Berechtigungen. |
| !event_data.TargetDomainName: "Window Manager" | Dadurch werden Anmeldungen aus dem Desktop Window Manager gefiltert, der Teil von Windows 8 und Windows 2012 ist. |
| !event_data.TargetUserName:*$ | Dadurch werden Anmeldungen von verwalteten Dienstkonten gefiltert. Das nachgestellte Dollarzeichen ist für verwaltete Dienstkonten reserviert . |
| !tags:"dc" | Dadurch werden Anmeldeereignisse von unseren Domänencontrollern gefiltert. Wenn sich ein Benutzer bei einer Domänenarbeitsstation anmeldet und seine Anmeldeinformationen nicht lokal zwischengespeichert werden, wird sowohl auf der Arbeitsstation als auch auf dem Domänencontroller ein Anmeldeereignis generiert. Dieser Filter verhindert, dass wir die Anzahl der erfolgreichen Benutzeranmeldungen doppelt zählen. |
Die oben gezeigte Datentabellenvisualisierung wurde mit dieser Filterliste erstellt. In der Datentabelle werden mithilfe von Aggregationen die Gesamtzahl der Anmeldungen pro Benutzer, die Anzahl der eindeutigen Computer, an denen sich der Benutzer angemeldet hat, und die Anzahl der eindeutigen Quell-IPs gezählt, die in diesen Anmeldungen verwendet wurden (wenn der Benutzer remote war).
Die Tabelle kann verwendet werden, um Konten zu erkennen, die möglicherweise gefährdet sind. Wenn ein Konto verwendet wurde, um sich bei einer ungewöhnlich hohen Anzahl von Computern in Ihrem Unternehmen anzumelden, ist eine weitere Untersuchung erforderlich, um festzustellen, ob das Konto zum Crawlen des Netzwerks verwendet wird.